本文共 1201 字,大约阅读时间需要 4 分钟。
版权声明:请尊重个人劳动成果,转载注明出处,谢谢!
Map家族的继承关系
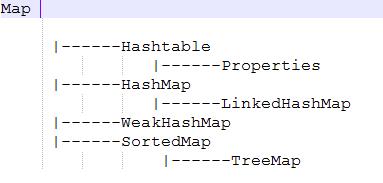
1 . TreeMap
TreeMap实现SortMap接口,能够把它保存的记录根据键排序, 默认是按键值的升序排序(自然顺序),也可以指定排序的比较器( Comparator ),当用Iterator 遍历TreeMap时,得到的记录是排过序的。
注意,此实现不是同步的。如果多个线程同时访问一个映射,则其必须 外部同步。这一般是通过对自然封装该映射的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSortedMap 方法来“包装”该映射。最好在创建时完成这一操作,以防止对映射进行意外的不同步访问,如下所示:
SortedMap m = Collections.synchronizedSortedMap(new TreeMap(...));
2 .HashMap
键和值都可以是空对象
不保证映射的顺序,多次访问,映射元素的顺序可能不同 非线程安全3 .LinkedHashMap
内部维持了一个双向链表,可以保持顺序
此实现不是同步的。如果多个线程同时访问链接的哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须 保持外部同步。这一般通过对自然封装该映射的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedMap 方法来“包装”该映射。最好在创建时完成这一操作,以防止对映射的意外的非同步访问:
Map m = Collections.synchronizedMap(new LinkedHashMap(...));
LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.也可以在构造时用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
4 .使用场景
一般情况下,我们用的最多的是HashMap
HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。
TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列,像连接池中可以应用。